Platform Overview
Empirical is the only exposure management vendor that publishes a false positive rate and measures performance. Our platform trains predictive models on near-real time exploitation telemetry and your enterprise's own data (assets, applications, controls, patching cadence) to produce calibrated probabilities of exploitation that you can measure, test, and defend to your board.
Request Demo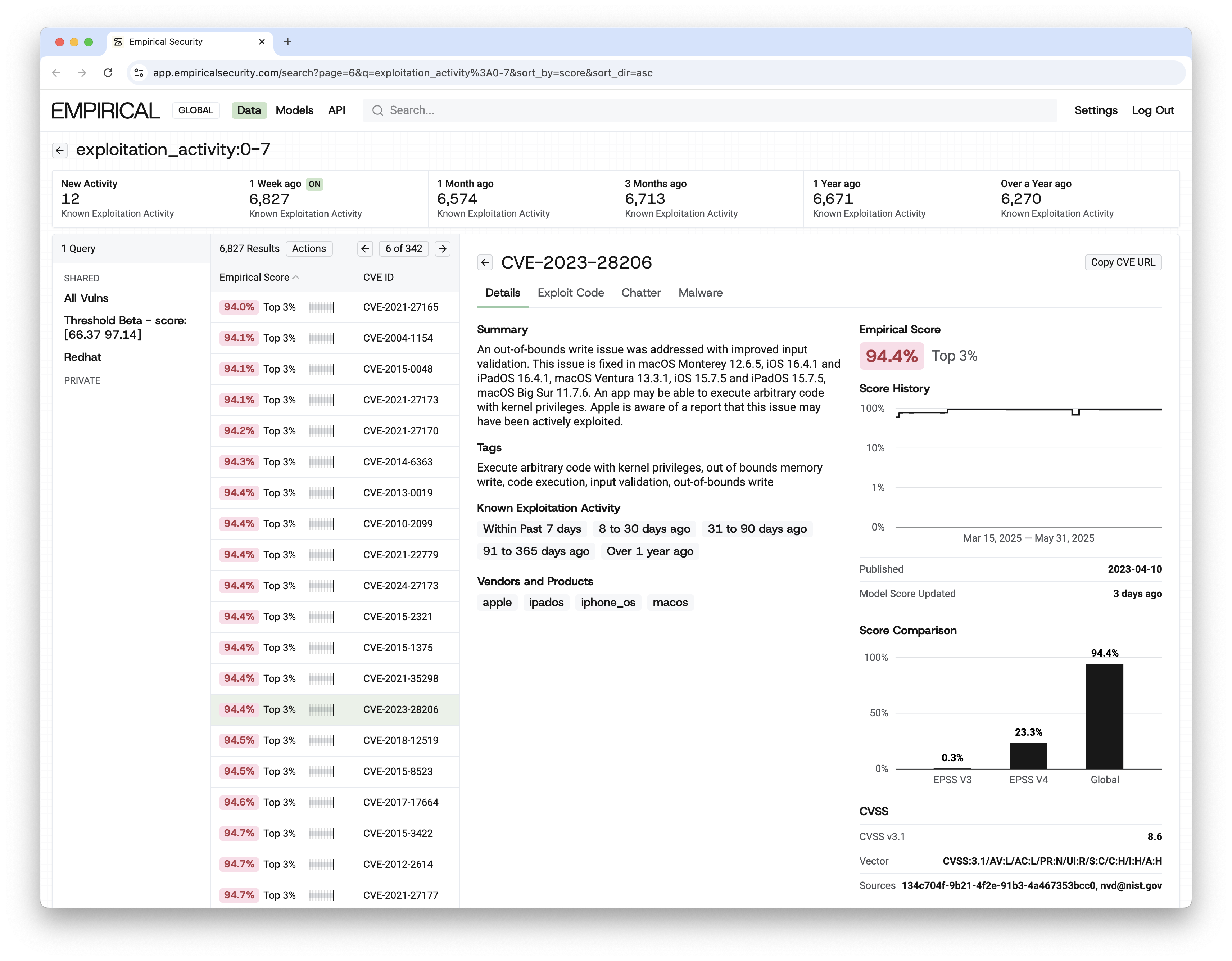
How It Works
Our platform supports Empirical's global and local models. The global model, trained on ~2 million exploitation events, captures attacker behavior across the internet. Local models, trained on your environment's telemetry, capture more targeted attacks. The two models work together to surface the vulnerabilities most likely to be exploited in your infrastructure.

External Data


Models


Local Data

Platform

UI

API

Agent
External Data
Local Data
Models
Platform
UI
API
Agent
External Data
Empirical monitors exploitation activity across 17,000+ CVEs. We observe exploitation as it happens and changes.
• 17,000+ known exploited vulnerabilities, tracked in near-real time
• Hourly exploitation telemetry per CVE, with years of historical depth
• Millions of malware hashes correlated to specific CVEs
• 1,400+ OSINT sources
• Ground-truth data from the team that built EPSS
Models
Our models are statistical learning systems that produce measurable predictions with coverage and efficiency that you can verify.
• Local Model: trained on your assets, your controls, your environment to determine which findings pose real risk to you.
• Global Model: trained on internet-scale exploitation data to forecast attacker behavior.
• Together: higher coverage, higher efficiency, fewer wasted cycles.
Local Data
Empirical ingests scan results, asset metadata, compensating controls, patching velocity, network topology and uses that data to train a model only you can access.
• We ingest your scanned assets and vulnerability findings.
• We evaluate your environmental telemetry and compensating controls.
• Your local model improves with every month of data.
Platform
Explore your security data with known exploitation activity through our web interface. Retrieve the latest intelligence via API. Automate triage with our AI agent.
Use Cases
• Threat Intelligence
• Vulnerability Management
• Application Security
• Cloud Security
Effort, Coverage, and Efficiency
CloseAll Published Vulns (CVEs we could prioritize)

Effort
Measures the relative workload as the proportion of vulnerabilities prioritized out of all the possible CVEs:
Correctly Prioritized + Incorrectly Prioritized / Everything
Efficiency
Measures how accurately our strategy focuses on vulnerabilities that have exploitation activity:
Correctly Prioritized / Correctly Prioritized + Incorrectly Prioritized
Coverage
Measures how well our strategy covers the vulnerabilities we prioritized from all vulnerabilities that show exploitation activity:
Correctly Prioritized / Correctly Prioritized + Incorrectly Ignored
Why security teams choose Empirical

A common language for risk decisions
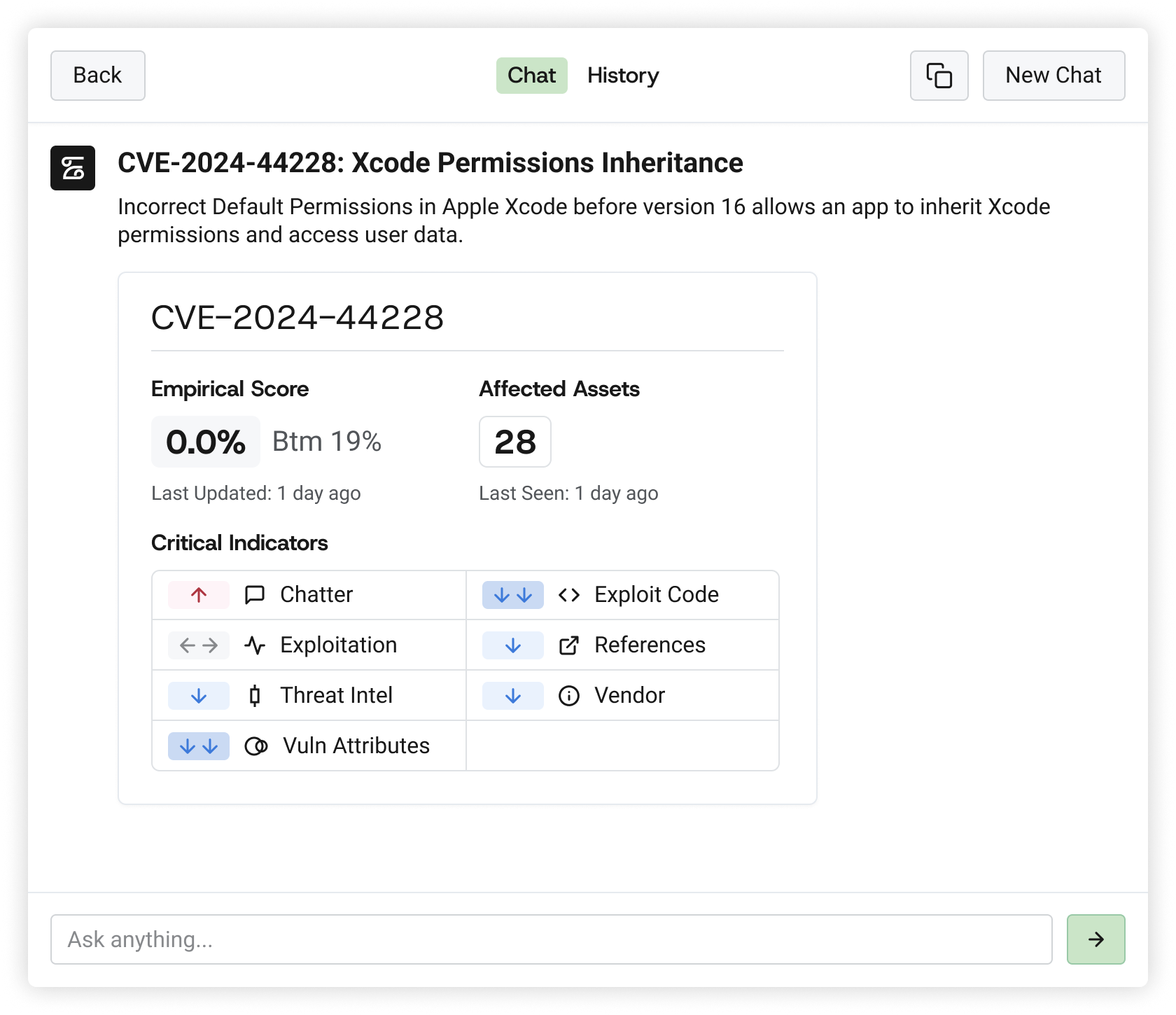
The Empirical global model grounds every prioritization decision in observable evidence. When someone asks "why are we fixing this one first?" The answer is a probability backed by real world exploitation telemetry, with critical indicators explaining the logic in real time.

Your context changes the answer
A critical vulnerability behind a WAF with no internet exposure is not the same risk as a medium CVE on an unpatched, public-facing server running your payments stack. Generic models can't tell the difference. Our local model can because it trains on data only your environment produces.

We predict which vulnerabilities will be exploited in your environment.
CVSS measures severity, and EPSS predicts global exploitation probability, but neither tells you what will be exploited in your environment next month. Our models answer this crucial question. We demonstrate higher coverage and efficiency than traditional methods or off the shelf models. When fixing a limited set of vulnerabilities our predictions catch more of what actually gets exploited and waste less effort on what doesn't. We publish the data to prove our performance.
Platform Capabilities
01
Switch models instantly
Toggle between local, global, and EPSS views. See how each model scores the same CVE and understand why they diverge.
02
Full model transparency
Every data point contributing to a score is exposed. No black boxes. Inspect the features, question the output, trust the result.
03
Validate threats with exploitation evidence
Cross-reference any CVE against real-time exploitation indicators: active campaigns, malware associations, exploit maturity, attacker infrastructure.
04
AI agent for workflow automation
Ask our agent to triage findings, generate remediation plans, draft exception requests, or surface emerging threats grounded in the Empirical model's output, not hallucinated from irrelevant data.
05
Connect any security tool
Ingest from scanners, CNAPPs, EDR, CMDB, ticketing systems, and cloud platforms. The model improves with every source you connect.
06
17,000+ exploited-in-the-wild CVEs
The largest curated exploitation dataset in the industry. 12× CISA KEV. Built from the same ground-truth collection that powers EPSS.
07
Near-real time exploitation telemetry
Models update with hourly exploitation signals. Not daily. Not weekly. The threat landscape moves in hours. So does the model.
08
Forward-deployed data science team
Our team includes the creators of EPSS and the founders of risk-based vulnerability management. They work directly with customers to tune local models, validate results, and drive measurable risk reduction.
FAQ
How does the platform discover assets?
Empirical integrates with your existing asset inventory (CMDB, EDR, cloud APIs, scanners, container registries). We don't replace your discovery tools. We unify their output into a single asset graph that feeds the local model with the environmental context it needs to score accurately.
Does it map vulnerabilities to business impact and critical assets?
Yes. The local model ingests business context, asset criticality, data classification, regulatory scope, service dependencies, alongside technical vulnerability data. This means a CVE affecting a payment-processing server is scored differently from the same CVE on a development sandbox, even if the CVSS score is identical.
What integrations are available?
The platform supports integration with major vulnerability scanners (Qualys, Tenable, Rapid7, CrowdStrike), cloud security tools (AWS, Azure, GCP native), ITSM platforms (ServiceNow, Jira), EDR/XDR solutions, and SIEM/SOAR systems. Our API and AI agent extend integration to any system with an API endpoint and MCP server.